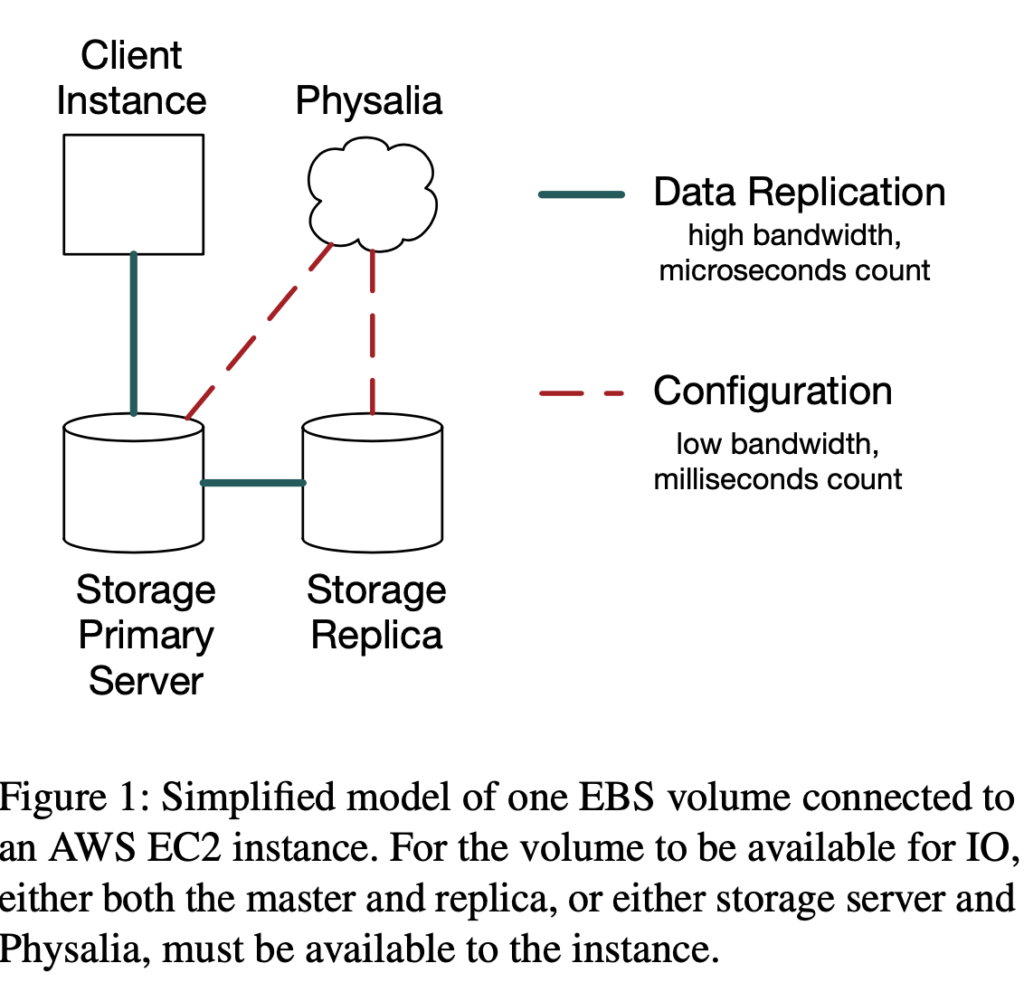
A few days ago, OpenAI released a chat-based model called ChatGPT and provided an interface for users to interact with. ChatGPT is a form of conversational AI where you can ask questions or have a conversation with a bot backed by a model. As per the announcement –
The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests
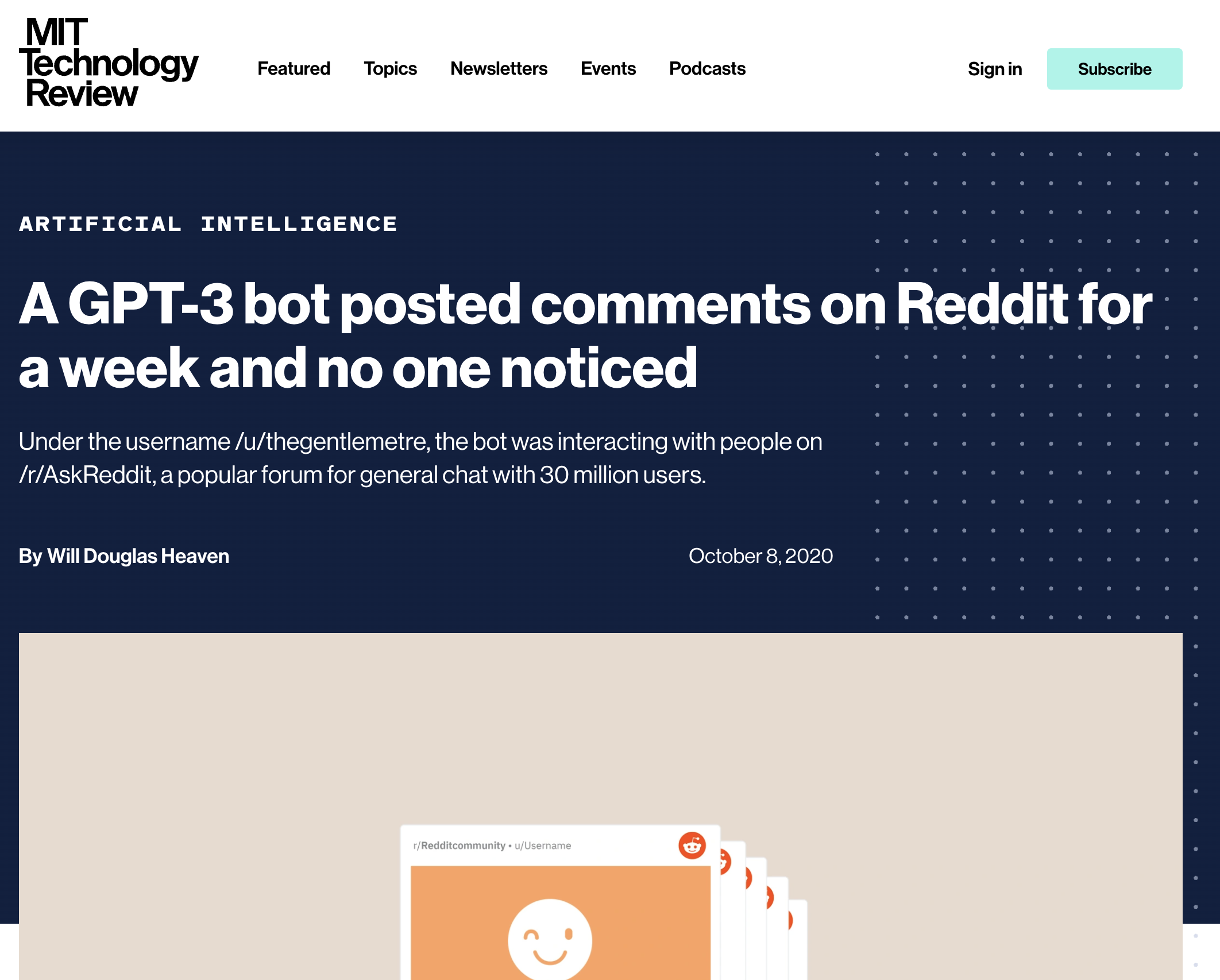
The last time I was this excited by GPT was when a GPT-3 bot was posted comments in AskReddit and no one realized that those comments were from a bot.
Over the weekend, I decided to give this GPT-3.5 (should we start calling these with a T-prefix, like T-1000?) a spin. Needless to say, it has been impressive. I plan to use this bot as a tool in my daily usage (a friend remarked that they would use it to generate poems for holiday greeting cards!).
Following is one such interaction I had with ChatGPT:
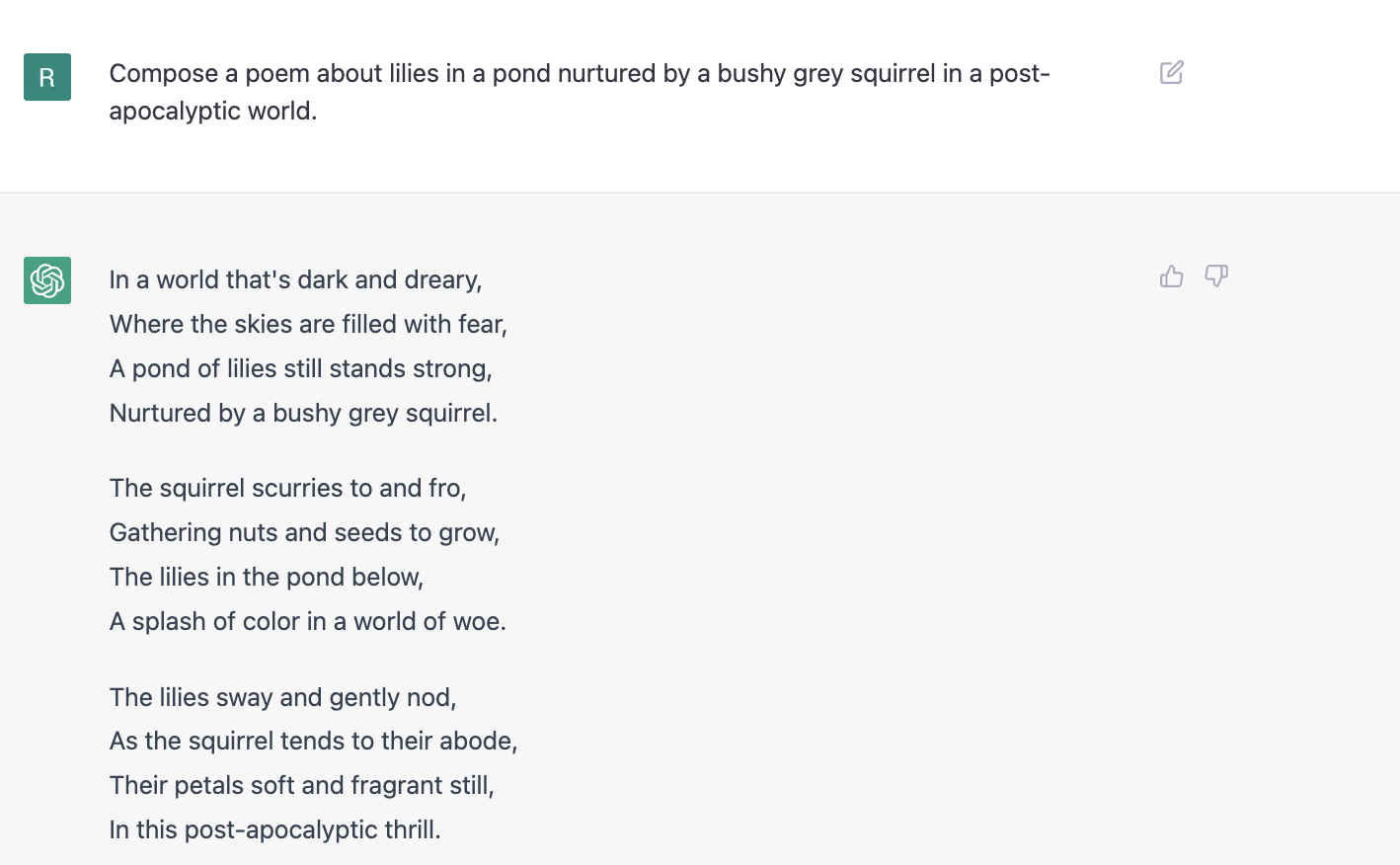
As you can observe above, the ChatGPT maintains context from one conversation to the next, though as per the information on the site, it does not personalize. In other words, it is not tailoring responses based on the types of questions asked in the past by the human user. Every session opened at https://chat.openai.com/chat starts anew without any history or memory.
Still, with context maintained within a session, this model of Q&A for information retrieval seems more natural than one with search engines where personalized results lack connection from one to another. The shift from a command/query based structure to a conversational one is very empowering since latter mimics a dialogue between instructor/student or parent/child. As humans tend to be exploratory when researching any subject (or even shopping), the conversational approach is also more practical.
Also, as the research preview blog post indicates, there is an emphasis on safety with several mitigations in place compared to its older sibling InstructGPT (and there is also a contest to provide more feedback). In my tests, the model tends to be aware of bias and avoid generating any replies that may have been inferred (and thus possibly biased) than factual in nature.
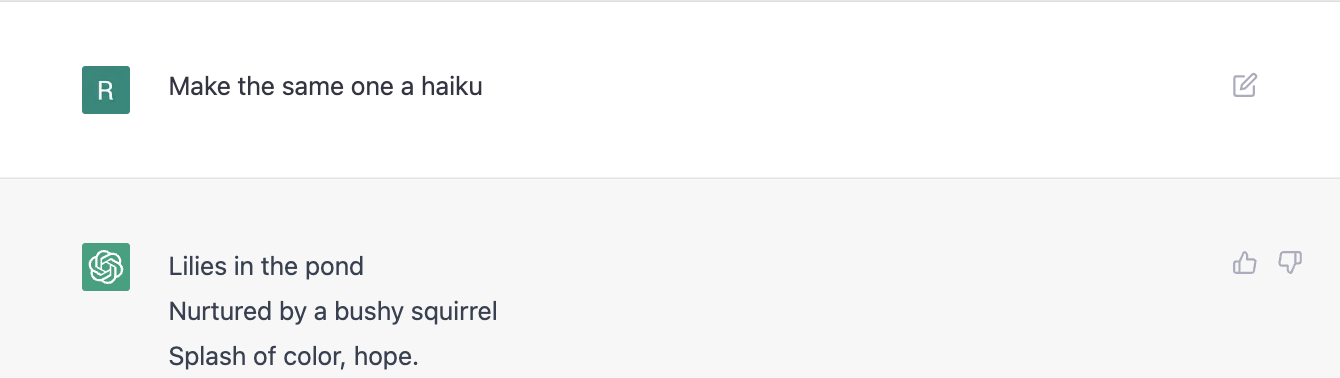
Finally, the multi-lingual support also seems to be good –
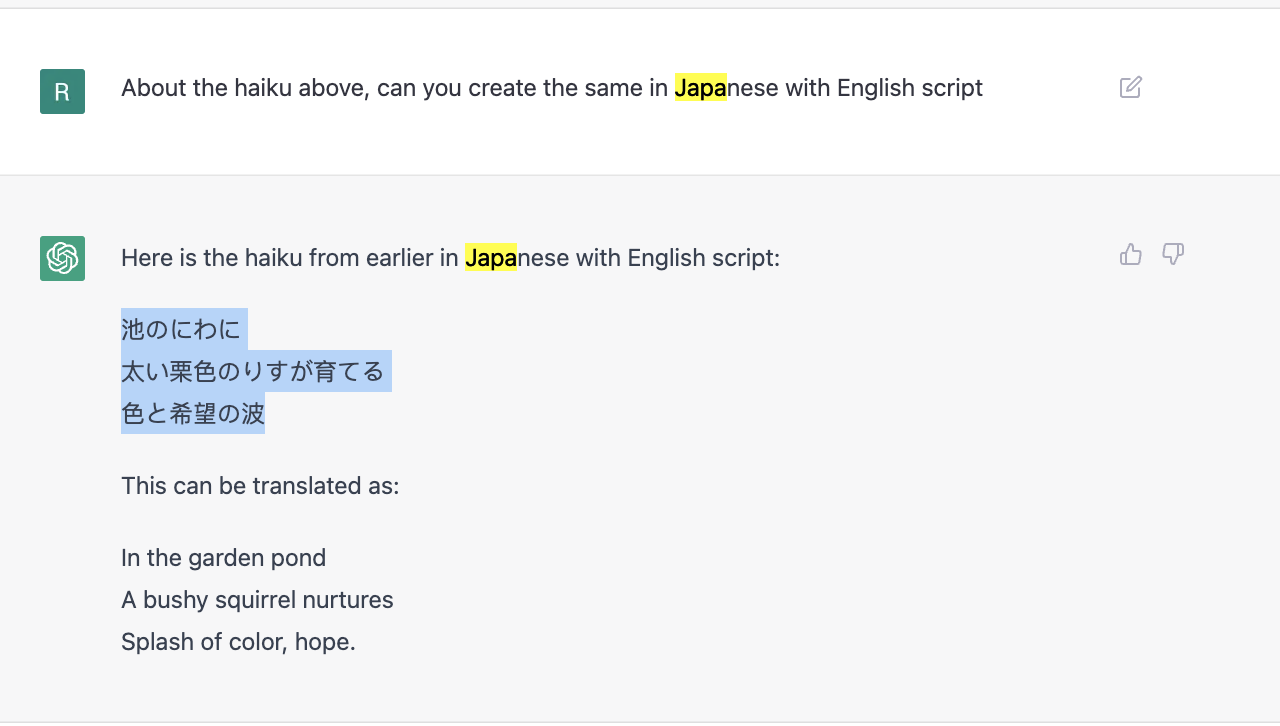
I further asked for the same haiku to be composed in the style of the famed poet Matsuo Basho

Note the subtle changes in the style of the haiku!
The model is also aware of its limitations in terms of what it has been trained on or its capabilities.
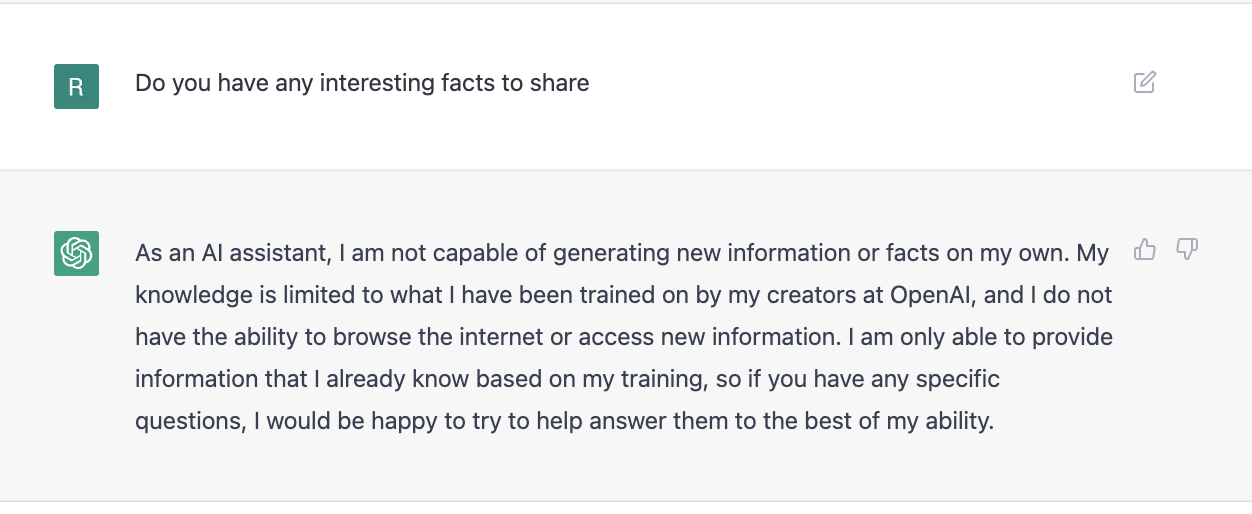
When asked about a word and a follow-up question on recent history (currently chatGPT seems to be not aware of time or its passage) –
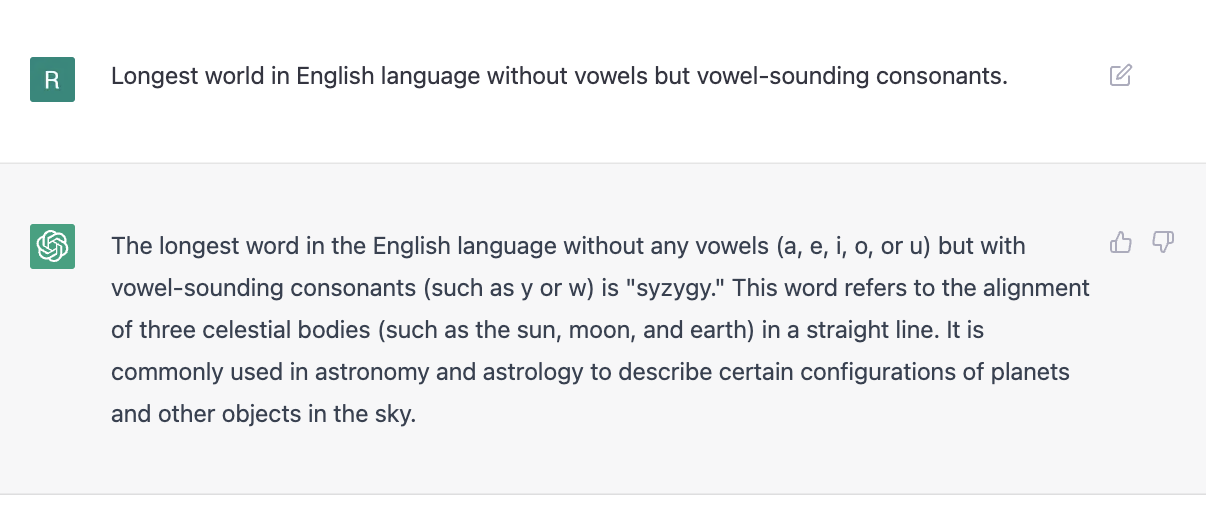
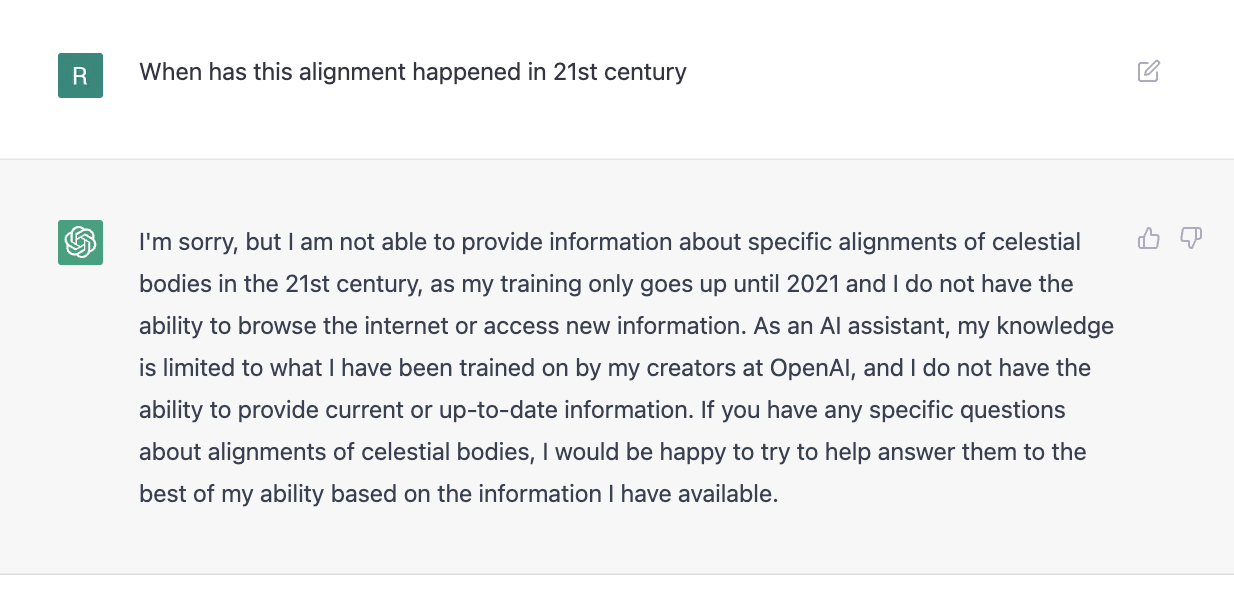
Overall, this is a very exciting development in the conversational AI space. With the rapid growth in AI model sizes, the future seems very promising. Past experiences have not been equally exciting either due to those being solely voice-based (which has not been accurate in parsing even with personalized voice models) or due to lack of a web-based (or even a dedicated app-based one) interface.
While it does seem like Google search is facing serious competition here, there are still a few gaps to ponder over –
- The model is trained on a static model of documents, code, and text corpora. In other words, it does not evolve or update itself in real time. It will be interesting to observe the accuracy and capabilities of ChatGPT in an iterative mode.
- Since it is not connected to the Internet, the boundaries of its knowledge are well-defined and known. If it needs to be a real-time search engine, these “boundaries of knowledge” may be hard to define. More importantly, only time will tell if these safety mitigations continue to safeguard all the generated responses, especially if they are being generated in real time.
- Personalization may be helpful where responses are tailored to the user asking the questions based on history. Care needs to be taken to avoid any filter bubbles by being explicit about it: providing a generic answer and a personalized one separately. Privacy is another aspect to balance when it comes to personalization.
- The interaction here is equivalent to a “I am feeling lucky” in a search engine. At the same time, users may be more interested in all sources of information than the most pertinent ones. This behavior can happen since we often may not know what we are looking for until we examine the choices. In this sense, a hybrid mode of a chat-based answer with a list of results on the side seems ideal. Google is already providing handy solutions in response to search queries, but usefulness can be improved with a chat-based interface such as ChatGPT.
Note that in the comparison above, I have excluded the analysis of ChatGPT’s prowess when it comes to code (powered by Codex, which also powers Github CoPilot), where it seems to have no other parallels to compare to.
When it comes to voice assistants, there is much to be said in terms of conversation since the human voice tends to be much richer than text in terms of tone, intonation and many similar characteristics which convey a lot too.
There are questions being asked whether chatGPT can achieve AGI which will make that AI to to be completely indistinguishable from a human in all the traits while being much more efficient and scalable. While it will be a matter of time – question of when and not if – before such a parity is reached, we need to avoid underestimating the usefulness of chatGPT-like tools for humans as a powerful force multiplier.
Augmentation of humans with a powerful AI has been in the realm of science fiction (Daedalus from Deus Ex to pick one) and research papers such as this one from Doug Engelbart from the 1960s (thanks to Notion’s post on their AI assistant for pointing me to this). It is about time when that futurism starts converging with the present.
Finally, from a futuristic standpoint, the NorthStar in this space has to be Star Trek’s onboard computer (voiced by Majel Barrett in multiple episodes) which really understands the speaker, converses with them, and remembers them individually between interactions.