
I often take notes and jot down observations when I read academic/industry papers. Thinking of a name for this series ‘Gossips in Distributed Systems’ seemed apt to me, inspired by the gossip protocol with which peers in these systems communicate with each other which mimics the spread of ideas and technologies among practitioners and people alike. The goal of this series would be to do a round-up of any new concepts or papers in computer science (often in distributed systems but not always) and share my thoughts and observations.
Today, we are going to talk about the Physalia paper from AWS: “Millions of Tiny Databases”. This is inspired by Physalia or Portuguese man-of-war (pictured), a siphonophore, or a colony of organisms. Overall, the paper, even though slightly on the longer side, is chock full of details and best practices pertaining to design, architecture, and testing of distributed systems.

Given the size of the paper and the wide gamut of topics that it touches, we will be discussing only a few aspects of the paper in this post along with some observations. In subsequent sequels, we will go into others in further detail.
Before proceeding ahead, the present EBS architecture with Physalia has a primary EBS volume (connected to EC2 instance) and a secondary replica, and data flowing from instance to primary and replica in that order. Also, this chain replication is strictly within an Availability Zone (AZ) mainly due to inter-AZ latencies being prohibitive. The pre-Physalia architecture had a similar replication chain but with the control plane also being part of EBS itself rather than a separate database (which we will soon find out was not a good idea).
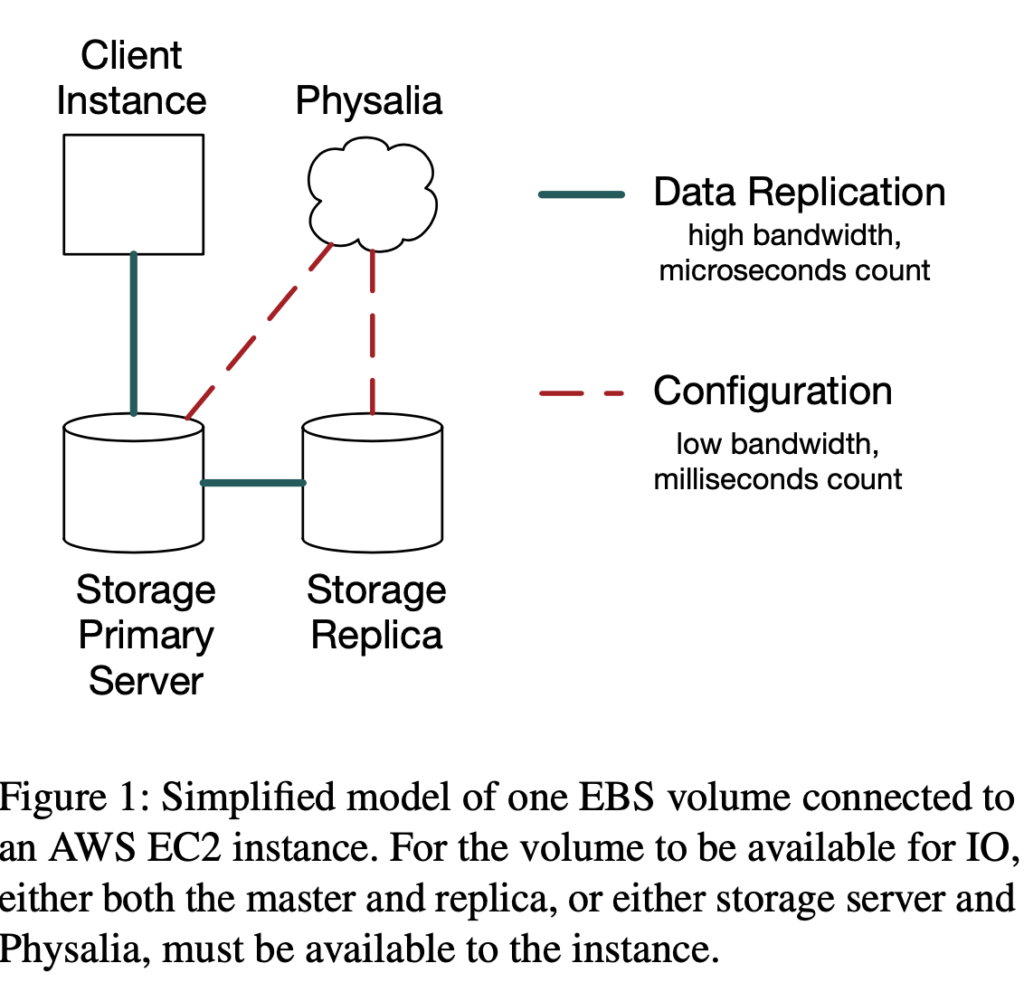
Raison d’être
All good-to-great systems have a story that necessitated their existence. In this case, it was an outage of the us-east-1 region in 2011 caused by overload and subsequent cascading failure which necessitated a more robust control plane for failure handling. The postmortem of that outage is here, it is quite long and wordy, so I will summarize it here.
In short, it started with a network change that turned off the primary network and overwhelmed the secondary one. This introduced a network partition in the EBS cluster, causing a sharp spike in re-mirroring requests. Re-mirroring involves re-designation of primary replica based on consensus between EC2 instance, volumes, and control plane. Even after the network partition was restored, there was a sudden spike (“thundering herd”) in re-mirroring requests from “stuck volumes”. Due to a bug in EBS code dealing with a large number of requests and lack of backoff in request retries, there was a sudden shortage of EBS space availability since nodes started failing due to the bug. It also seems like the number of “stuck” volumes increased due to the control plane getting overwhelmed.
Had it stopped at this, this would not have caused a region failure but the only failure of single AZ (which is often acceptable for well-architected systems). Remember, the pre-Physalia control plane spanned multiple AZs. Due to this storm, the control plane queue was saturated with a large number of long-timeout requests. This meant any EBS API requests (such as CreateVolume used by new instance launches) from other AZs also started to fail or suffer high latencies. To restore order, the affected AZ was fenced from the EBS control plane, and degraded EBS clusters were isolated in that AZ too to prevent the AZ degrading further. Interestingly, it seems like the EBS monitoring didn’t alert about EC2 instance launch errors in the time since it was drowned in alerts from degraded EBS clusters. In addition to EC2 and EBS, this also affected RDS which uses EBS internally.
Note that when a volume is “stuck”, I/O bound processes on the system will be blocked on I/O and processes can often end up in ‘D’ state’ (uninterruptible sleep on Linux).
The postmortem action items delve into various design changes for the long term, many of which (to quote one “an opportunity to push more of our EBS control plane into per-EBS cluster services”) culminated in the design of Physalia.
High Level Architecture
Driven by the above desire to localize the control plane, reduction of blast radius seems to be the topmost priority in Physalia, and accordingly, Physalia lies at cross proximity to its clients.
Physalia is a collection of millions of databases, each of which is a transactional key-value store dealing with a partition key corresponding to a single EBS volume and provides an API with strict serializability for reads and writes. Also, it is infrastructure/topology-aware – racks, datacenter, power domains – and is also placed in close proximity to EBS primary and secondary replicas relying on it. The primary goal behind this proximity is to reduce the impact of network partitions while maintaining strong consistency. The focus is also on reducing blast radius without decreasing availability. The load profile on this is asymmetrical, ie. when things are good there isn’t much traffic but during large-scale failures, there is a bursty latency-critical workload. In addition to other goals, misuse resistance – ensuring that the system cannot be misused and to limit damage under misuse – is also deemed important.
Zooming into each Physalia, there is a colony of “cells” sharing various caches. Each cell (a logical construct) serves one EBS volume and is 7 ways replicated (empirically determined in the paper) with Paxos protocol between the nodes (nodes correspond to servers). Each node can have different types of cells corresponding to different EBS volumes, this ensures node failures do not bring down any volume.
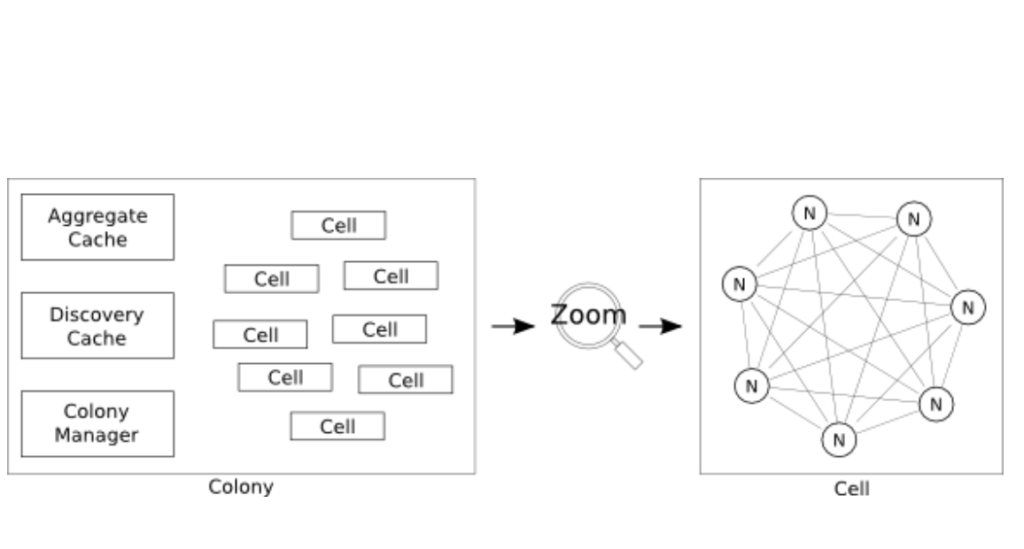
Deployment and Operational Concerns
In addition to this, to protect against iatrogenic causes (IOW, issues caused by interventions such as deployments, patching, etc.) of outage and downtime, nodes are assigned different colors and ones of different colors don’t talk to each other. Cells are also constructed from nodes of the same color. To isolate from any failures during deployment within a datacenter, deployments proceed color-by-color. Since colors are assigned randomly to cells, this insulates against any specific software failure or hot-spots prevalent in these systems (80% of the load from 20% of clients or similar tailed distribution).
Since Physalia cannot distribute across multiple DCs or regions, crash-safety is a strong requirement. This reminds me of crash-only software. Hence, a custom implementation written in Java is used which keeps state both in memory and disk, probably like ZooKeeper which this paper credits as well. It would be interesting to see if non-GC heavy languages were considered given the mentions of partitions from GC pauses and workarounds for it. There may have been other constraints behind this decision.
In terms of queuing, as noted earlier, batching and pipelining take place within each cell. To avoid hitting performance degradation from increased contention and coherence, taking a leaf from Universal Scalability Law (USL), requests seem to be rejected outright. This dropping behavior reminded me of the CoDel algorithm prevalent in networking systems. On the client front, it seems now (as opposed to pre-outage or during the outage) they implement jittered exponential backoff (one of the paper’s authors has a blog post on Exponential Backoff And Jitter which I highly recommend). With this, they are keeping the load bounded at cost of higher latency (though I presume this needs to be bounded too given tight constraints on Physalia latency).
Store and API
In terms of API, it offers a typed key-value store with support for strict serializable reads, conditional writes, atomic increments, and so on. There is also the provision to batch reads/writes in a single transaction. Much like Cassandra, any API only allows addressing one partition key at a time which is an acceptable optimization.
Interesting to note that floating-point is not supported in data types due to the non-portability of floating types across hardwares and versions. This is not new and has been seen in other database systems too in the past (MySQL bug#87794). But, I was surprised to see this in portability-focussed Java VM.
Unsurprisingly, SQL is also not supported. In my opinion, there is simply no need to add SQL support if the client types fall into a very narrow band like here. Maybe if this is open-sourced in the future, then a SQL interface may be necessitated by other use cases.
A linearizable and serializable consistency is provided by EBS clients. For caches, monitoring and reporting an eventual consistency mode (with monotonic reads and consistent prefix) is provided. Note that, not all eventually consistent modes are the same, and there is a lot of nuances involved. I strongly recommend checking the consistency model tree from Jepsen.
Time-based leases (which I gather are similar to etcd or zookeeper leases) are provided but are used in non-critical paths due to clock skew. Clock skew can introduce latency in quorum based systems, the chapter on Unreliable clocks in Designing Data-Intensive Applications book elucidates this further.
We have reached the end of this installment of Gossips in Distributed Systems. Next time, we will look at the reconfiguration of Physalia (which is important since even in normal conditions, EC2 instances have a shorter life than volumes implying detach/attach of volumes between instances), topology awareness, and placement, poison pills, testing with TLA+ and so on.